
提到人工智能(Artificial Intelligence)一词,大家第一个闪过的印象可能是科幻电影那拥有人类智慧的机器人,或是电影钢铁人中的「贾维斯」智能助理。这些天马行空的技术的确都属于人工智能的范畴,但这其实只是人工智能其中一小部分的领域,它的应用面充斥在各种产业,早已和我们的生活密不可分。
AI 介绍与简史
一般称的 AI 其实是 Artificial Intelligence 的缩写,而这个名字也清楚地表达了它的涵义。人工智能的定义其实就是以「人工」编写的电脑程序,去模拟出人类的「智慧」行为,其中包含模拟人类感官的「听音辨读、视觉识别」、大脑的「推理决策、理解学习」、动作类的「移动、动作控制」等行为。

AI 即是以「人工」编写的电脑程序,模拟出人类的「智慧」行为。
AI 这个词汇首次出现是在 1950 年,那时离现代电脑的发明也不过几年的时间,当时的人工智能做的不过是跑一些写好的逻辑程序、处理数学定理证明,应用其实并不广;此外,由于当时电脑体积庞大、性能又有诸多限制,人工智能发展很快就面临到瓶颈了。
沉寂一阵子后,在约二、三十年前,因为电脑储存空间、运算性能的突破,AI 重新回归主流技术发展重点,开始出现「机器学习」这块领域,并得到了很好的成果,如发展出「支持向量机(SVM)」模型,能有效分类处理各种数据;到了最近几年,又因为技术与演算法的进步,再度发展出「深度学习」这个领域,AI 的成长俨然已成为不可忽视的巨兽!
写到这里,读者是否开始对逐渐出现的名词感到困惑呢?别担心,以下会用简单的方式向各位介绍。
AI 的应用与技术内容
AI 功能的身影已经充斥在我们的生活,它的样貌已不再那么的神秘,交通、娱乐、医疗等领域,到处都可见其踪影,以下举几个例子让大家更了解 AI 的样貌:
- 手机助理语音识别功能
- 社交媒体上的广告投放
- 串流影音网站的推荐(如 youku 推荐影片、西瓜视频 精选)
- 高德地图 最佳路线规划
要如何让电脑实现以上的功能呢?这边介绍一些常见 AI 的运行原理:
- 搜索:寻找最佳路径、最短运算的搜索方法,用来加快电脑的运算或减少内存的负担,如 BFS 优先广度算法、A star(A*)算法等。

A* 算法展示
- 逻辑推论:为了让电脑能进行推理、抉择、修正,发展了许多逻辑推论系统,最广为大家使用的就是布林运算,其主要利用二元的运算符号(0、1)去定义逻辑的函数,相当方便直观,应用也很广泛。
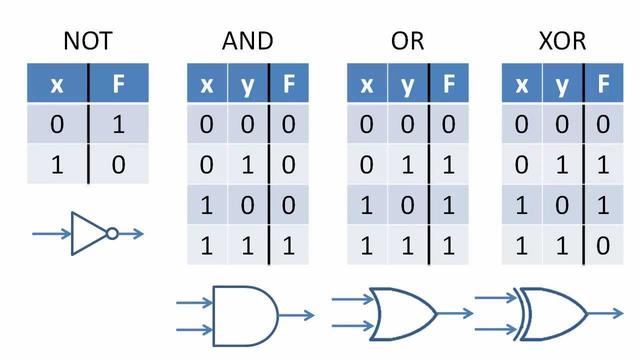
布林运算真值表
- 统计、机率:主要目的是通过机率统计数学模型,帮助分析资料、处理大量数据,如 EM 演算法、贝叶斯网络等。
- 神经网络: 模仿生物神经网络的结构与功能,可以通过输入的资料训练,产生对应的算法模型,学习判断指定的问题。
解析 AI/ML/DL 的关系
既然提到了神经网络,就不得不提及「机器学习 Machine Learning(ML)」、「深度学习 learning(DL)」, 这两个最近非常火热的名词了,究竟机器学习(ML)与深度学习(DL)到底差别在哪呢?
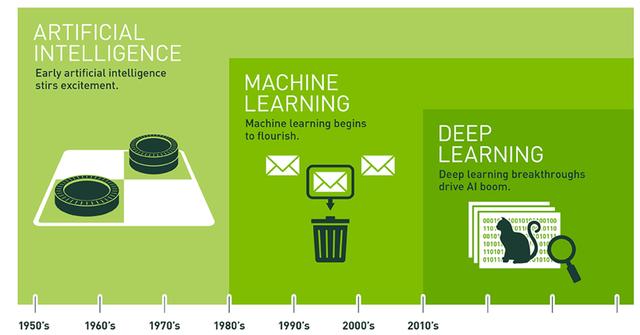
AI 演进
我们可以从上面这张图清楚理解,AI、ML、DL 这三个名词的关系就像洋葱一样层层递进,机器学习(ML),是人工智能(AI)底下的技术分支,而深度学习(DL)是近年才从机器学习衍生出的领域,可以比喻为俄罗斯套娃,一个子领域之中又有更深入的子领域。
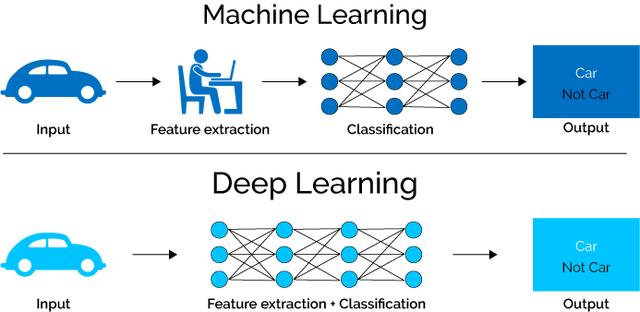
机器学习与深度学习的训练比较
上图 / 机器学习与深度学习的训练比较:机器学习需要人为特征分类(Feature extraction),而深度学习则是交给模型自己处理分类。
机器学习
简单来说,为了让电脑通过自我学习的方式,去解析数据或做出问题判断,不断优化改进自身,而非单纯写好程序,仅处理单一特定问题,其中其实包含了许多学问,如统计、机率、算法、逼近理论等多项领域。
传统的机器学习结构:资料→特征提取→模型→答案
为了达到预测的效果,机器学习会不断让模型最佳化去拟合资料,然而在特征提取上,仍然需要通过手动去标记特征,将特征转为编码或向量形式后,再通过机器学习的模型去处理,最后得到预测结果。
机器学习在资料分析上已经发展得非常成熟。举例来说,如果将蓝球和红球都丢入袋子里,要如何完美的划出一条线将他们分割呢?这时通过机器学习的模型——向量支持机(SVM)处理,就能将所有的球拉到更高的维度做切割,让原本散乱的球,在三维空间漂浮看起来,变得容易分类。
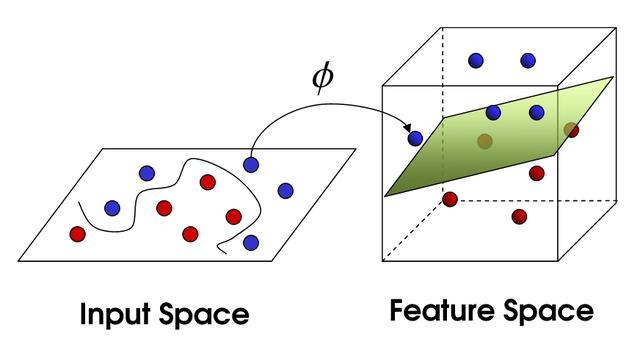
SVM 分割示意图
然而在处理影像识别或是复杂的分析上,机器学习还是有一定的限制,毕竟它所需要的特征都还是需要人为的特征分类,那么深度学习又是如何运作的呢?
深度学习
深度学习是通过神经网络(Neural Network)的方式来实践,而神经网络由无数个神经元串联所组成,这些神经元的运作方式和人类神经一样,一个连着一个传递讯号,只不过输入的不是生物电流,而是变数、权重(weight)、误差(bias);其中,每个神经元本身都是个小小的函数,资料会在神经网络中慢慢转化,最后得到我们的预测模型。
深度学习的结构:资料→模型(特征提取自学)→答案
与传统深度学习不一样的是,在特征提取的部分,我们把它交给神经网络去处理,让它在不断地反复运算中逐渐萃取出所需要的特征,不断改进模型本身权重,最后产生预测模型。这个步骤需要大量的反复运算,也就是为什么深度学习领域到这几年随着 GPU 技术的突破,才又突飞猛进的进步!
以「猫狗识别」举例,深度学习的训练只需将标记好类别的影像输入到模型中,神经网络会自行将影像特征提取出来。那么这里问一个问题,如果这时候将「猪」的照片丢入,模型会给出什么结果呢?
A. 猫 B. 狗 C. 猪,想好了吗?

通过捲积神经网络训练猫狗识别
其实答案选 A 和 B 都对!由于神经网络训练的是猫狗模型,所以模型会按照它分类的特征去判别这只猪的照片,尝试让它在猫或狗之中选出一个答案(即使它不是猫也不是狗),所以这也是深度学习的限制,预测的模型主要仍取决于输入训练的资料,所以选 C 的各位,抱歉答错了!