
悄无声息,羊驼家族“最强版”来了!
与GPT-4持平,上下文长度达3.2万token的LLaMA 2 Long,正式登场。

在性能上全面超越LLaMA 2。
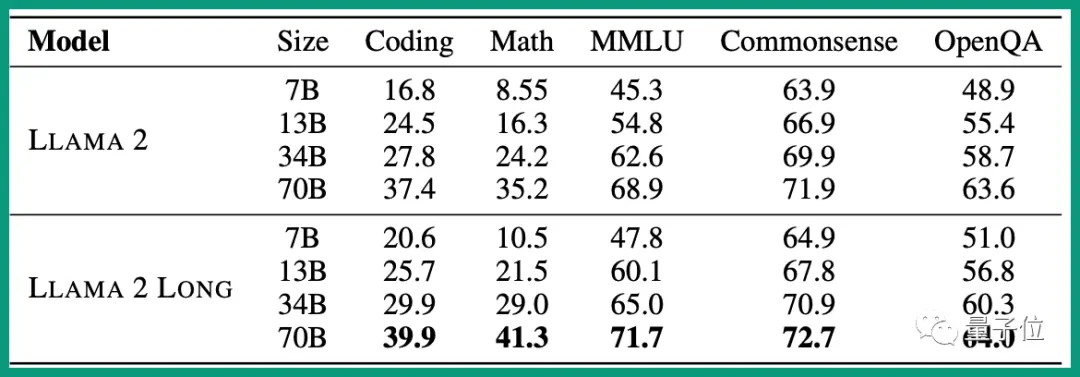
和竞争对手相比,在指令微调MMLU (5-shot)等测试集上,表现超过ChatGPT。
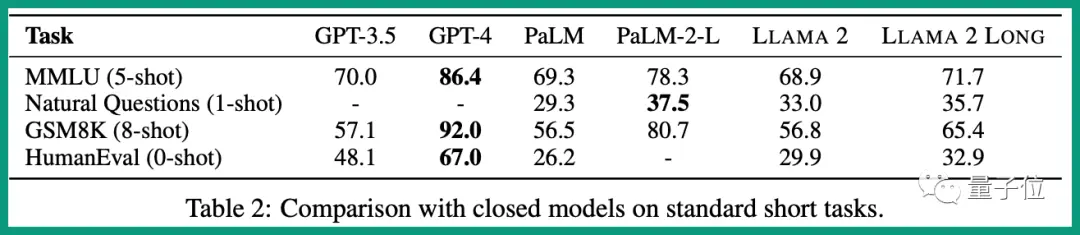
在人类评估(human evaluation)上甚至优于10万token的Claude 2,这个话题还在Reddit上引发了讨论。
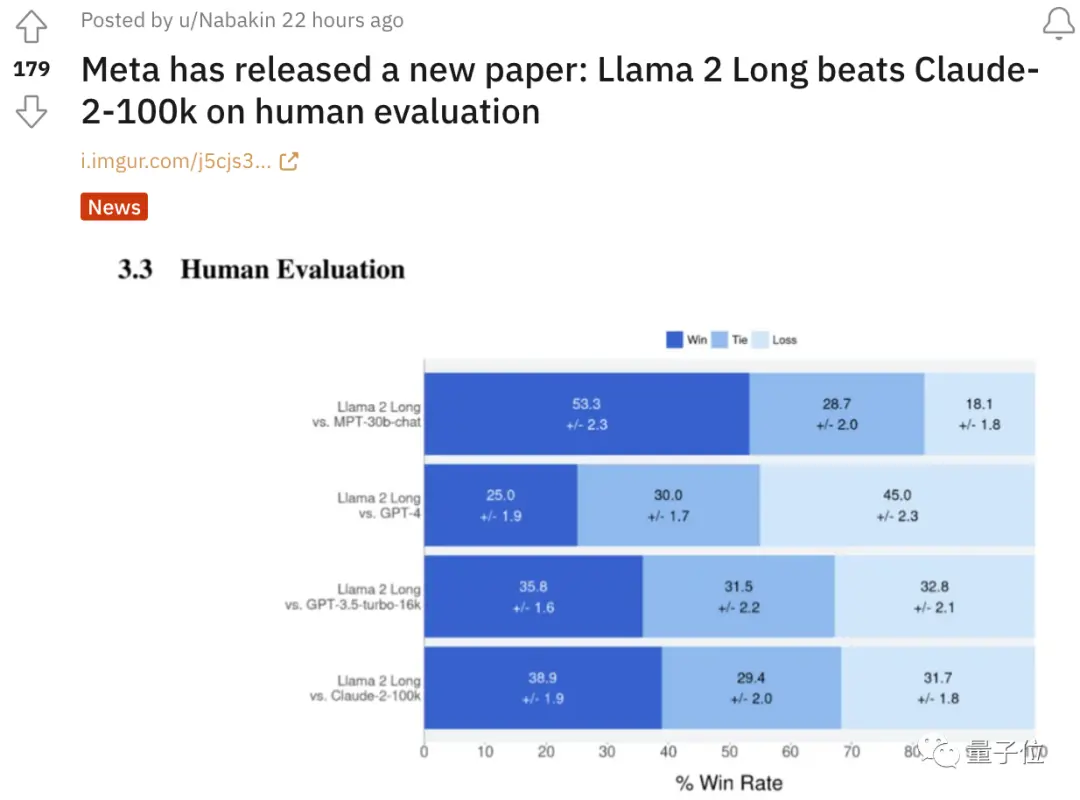
要知道,这些对比版本中,LLaMA 2 Long使用的最大版本也只有70B,远小于其他大模型。
这让人不禁感慨:Meta确实还是有两下子的。
也有人觉得,这才是最近Meta发布会的最大新闻啊,比Meta版ChatGPT要更令人兴奋。
论文介绍,LLaMA 2 Long使用了4000亿token语料加持下,并进行位置编码修改。
所以LLaMA 2 Long究竟是如何诞生的?
只对位置编码进行了一个非常小的改动
与LLaMA 2相比,LLaMA 2 Long的变化并不多。
一是训练参数上,采用了高达4000亿token的数据源。
——相反,原始LLaMA 2包含多个变体,但最多的版本也只有700亿。
二是架构上,与LLaMA 2保持不变,但对位置编码进行了一个非常小的必要修改,以此完成高达3.2亿token的上下文窗口支持。
在LLaMA 2中,它的位置编码采用的是旋转编码RoPE方法。
它是目前大模型中应用最广的一种相对位置编码,通过旋转矩阵来实现位置编码的外推。
本质上来说,RoPE就是将表示单词、数字等信息的token embeddings映射到3D图表上,给出它们相对于其他token的位置——即使在旋转时也如此。
这就能够使模型产生准确且有效的响应,并且比其他方法需要的信息更少,因此占用的计算存储也更小。
在此,Meta的研究人员通过对70亿规模的LLaMA 2进行实验,确定了LLaMA 2中的RoPE方法的一个关键限制:
即,阻止注意力模块聚集远处token的信息。
为此,Meta想出了一个非常简单的破解办法:
减少每个维度的旋转角度。
具体而言就是将超参数“基频(base frequency) b”从10000增加到500000。
这一改动立刻奏效,缩小了RoPE对远端token的衰减效应,并且在扩展LLAMA的上下文长度上优于一项类似的名为“位置插值”的方法(如下图所示,RoPE PI,衰减效果较为“隐含”)。