
有个著名咨询公司曾经预测过:未来只有两种公司,有人工智能的和不赚钱的。
它可能没想到,还有第三种——不赚钱的AI公司。
去年我们报道过“正在消失的机器视觉公司”,昔日的“AI四小龙”( 商汤、旷视、云从、依图),在商业化盈利上各有各的不顺。不过,随着GPT系列产品又掀起一股“大炼模型”的热潮,这些AI公司又支棱起来了。
商汤科技此前曾披露,下一步的发展战略是通用人工智能(AGI),继续推进“大装置+大模型”,并发布了1800亿参数的中文语言大模型 “商量”。

旷视科技也表态,会坚定投入生成式大模型的研发,保持核心技术能力长期领先。
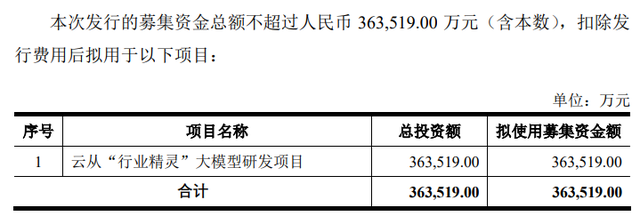
云从科技公开的定增预案中,为云从“行业精灵”大模型研发项目,募集资金不超过36.35亿元。
依图科技没有公开消息,但在此前的融资中曾因AI大模型和国产芯片等被看好。
无论是上一轮,以BERT、GPT-3为代表的“预训练+精调”大模型,还是此刻正红火的,以ChatGPT、GPT-4、文心一言等为代表的“预训练+精调+提示+RLHF(人类反馈)”的大语言模型,已经成为各大头部科技公司“秀肌肉”、相互竞争的重要工具。
谷歌、百度等大厂跑着入场,各路大模型“神仙斗法”。这场狂欢派对,成了机器视觉公司不得不玩、又玩不起的游戏。
尴尬的“长衫”
最近,CV公司参与到大模型这局游戏中,出现了这样的画风:语气一会儿大,一会儿怂。
在公开信息中,都表示自己会加大投入,去解决基础技术、基础问题。云从的管理者说要“投一二十亿解决算力问题”“我们是技术公司,研发投入不会低”;商汤的有关人士称,要做“统一化标准化的大模型”“加速构建通用人工智能的核心能力”;旷视也对标OpenAI,要“做影响物理世界的 AI 技术创新”。

谈到大模型技术和产品本身,底气又不足了。
这个说“基础大模型要有长期布局,NLP难点很多,短期内与境外领先企业会存在较大差距”,那个说“中国AI公司有商业化的压力,不能像OpenAI那样不计代价的创新”。
“预期管理”算是被你们玩明白了。
年轻人流行说自己是“脱不下长衫的孔乙己”,CV公司对于大模型这种不尴不尬的处境,其实也和“孔乙己”有相似之处。
CV公司在底层技术、基础设施、人才、资金、生态等领域的积累,不如头部科技企业优势显著。所以,自然也不可能真的跟谷歌、OpenAI、BATH(百度、阿里、腾讯、华为)正面打擂台,烧钱去做通用的基础大模型(foundation model)。
新一轮大语言模型,完整技术栈、工程实现能力、算力成本、数据积累等都有极高的门槛,AI公司自研大语言模型的难度前所未有。 OpenAI 在2022年就花掉了5.44亿美元,收入只有3600万美元,这是国内CV公司不具备的家底儿。
当然,外界也不应该过度放大CV公司的责任,非要将巨头才能承担的创新压力放在CV公司身上。
但是,CV公司又有着“AI-native原生企业”的光环,也确实积累了很多技术储备, 所以也不能直接躺平,像ISV集成商、软件公司一样依附大厂,欢欣鼓舞地等着集成或调用API就好。
昔日的“AI四小龙”还是要撑起“技术自立”的架子,努力融入这波炼大模型的热潮里,于是,又将模型数量和参数规模的比拼,拉升到了新的竞争水平。
比如云从有NLP、视觉领域的预训练模型,商汤在“AI大装置SenseCore”的基础上,构建的日日新大模型体系就包含了通用视觉模型、中文语言模型、图片生成模型……其中,仅“商量”大模型的参数规模,就和GPT-3差不多。
今天大家都感慨,孔乙己脱下长衫不容易,换个角度,“大模型”这件长衫,CV公司是不是有必要穿上呢?
玩不起的游戏
从2018年的预训练大模型到2023年的大语言模型,大模型走过了一个从萌芽到繁荣的小周期,种类、功能也丰富起来,我们已经见过很多AI企业、高校和科研机构、行业公司所打造的各种各样的大模型。