
ChatGPT横空出世后,RLHF成为研究人员关注的焦点。谷歌最新研究提出,不用人类标注,AI标注偏好后,也能取得与RLHF一样的效果。
如果说,RLHF中的「人类」被取代,可行吗?
谷歌团队的最新研究提出了,用大模型替代人类,进行偏好标注,也就是AI反馈强化学习(RLAIF)。

论文地址:https://arxiv.org/abs/2309.00267
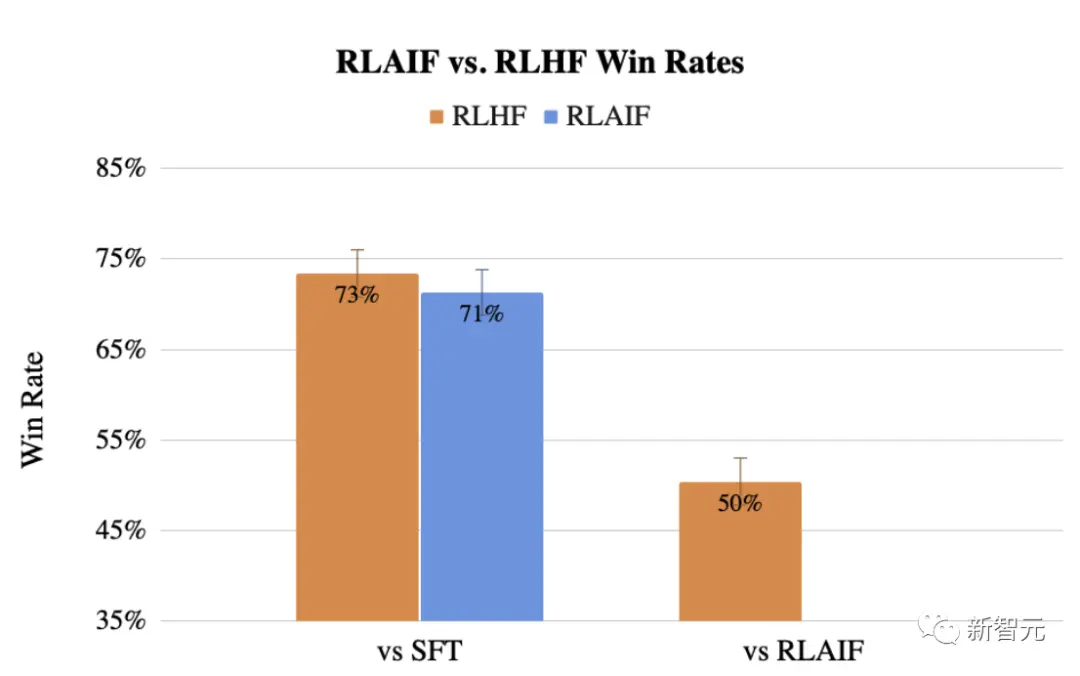
结果发现,RLAIF可以在不依赖人类标注员的情况下,产生与RLHF相当的改进效果,胜率50%。
同时,谷歌研究再次证明了RLAIF和RLHF,比起监督微调(SFT)胜率都超过了70%。
如今,大型语言模型训练中一个关键部分便是RLHF。人类通过对AI输出的质量进行评级,让回应更加有用。
但是,这需要付出很多的努力,包括让许多标注人员暴露在AI输出的有害内容中。
既然RLAIF能够与RLHF相媲美,未来模型不需要人类反馈,也可以通过自循环来改进。